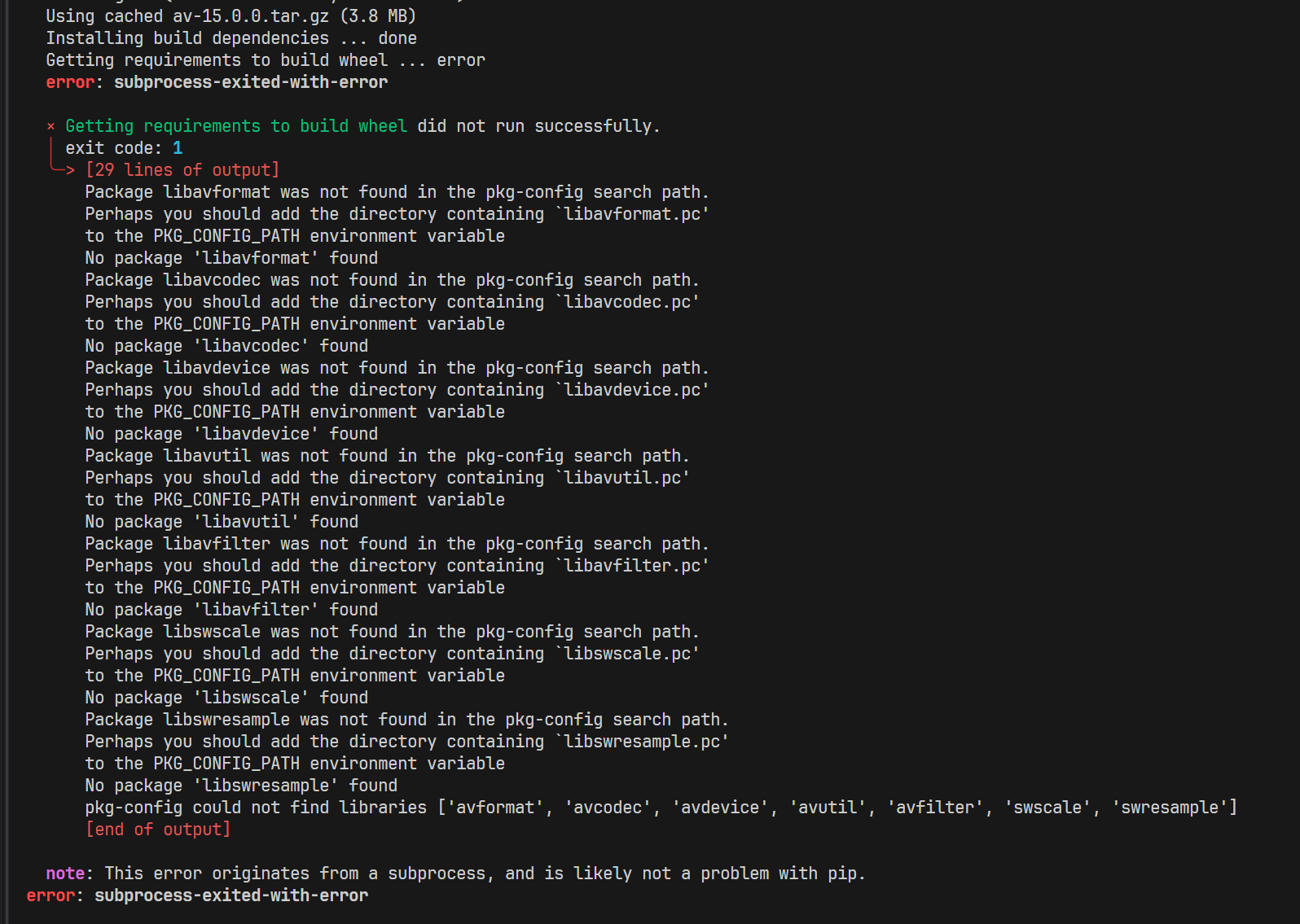
× Getting requirements to build wheel did not run successfully. │ exit code: 1 ╰─> [17 lines of output] Traceback (most recent call last): File "/work/home/huangnaixuan/.conda/envs/llm_finetune/lib/python3.10/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 389, in <module> main() File "/work/home/huangnaixuan/.conda/envs/llm_finetune/lib/python3.10/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 373, in main json_out["return_val"] = hook(**hook_input["kwargs"]) File "/work/home/huangnaixuan/.conda/envs/llm_finetune/lib/python3.10/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 143, in get_requires_for_build_wheel return hook(config_settings) File "/tmp/pip-build-env-86tzotxm/overlay/lib/python3.10/site-packages/setuptools/build_meta.py", line 331, in get_requires_for_build_wheel return self._get_build_requires(config_settings, requirements=[]) File "/tmp/pip-build-env-86tzotxm/overlay/lib/python3.10/site-packages/setuptools/build_meta.py", line 301, in _get_build_requires self.run_setup() File "/tmp/pip-build-env-86tzotxm/overlay/lib/python3.10/site-packages/setuptools/build_meta.py", line 512, in run_setup super().run_setup(setup_script=setup_script) File "/tmp/pip-build-env-86tzotxm/overlay/lib/python3.10/site-packages/setuptools/build_meta.py", line 317, in run_setup exec(code, locals()) File "<string>", line 21, in <module> ValueError: You are not using a virtual environment [end of output]
...... File "/work/home/huangnaixuan/.conda/envs/llm_finetune/lib/python3.10/importlib/__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "/work/home/huangnaixuan/.conda/envs/llm_finetune/lib/python3.10/site-packages/zmq/backend/cython/__init__.py", line 6, in <module> from . import _zmq ImportError: /work/home/huangnaixuan/.conda/envs/llm_finetune/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.30' not found (required by /work/home/huangnaixuan/.conda/envs/llm_finetune/lib/python3.10/site-packages/zmq/backend/cython/_zmq.cpython-310-x86_64-linux-gnu.so)
还有一个点是cxx11abi选项,它指的是 C++ ABI(应用二进制接口),cxx11abiTRUE 表示使用 C++11 ABI 编译,cxx11abiFALSE 则表示不使用 C++11 ABI 编译。不同的编译器和系统可能对 C++ ABI 有不同的支持,因此需要根据自己的环境选择合适的版本。这里我用FALSE的版本,